테렌스 타오의 AI 비유에 대한 고찰: AI와 인간의 성능 비교는 공정한가?
원문 출처: Terence Tao's Mastodon Post
1. 테렌스 타오의 원문 번역: AI 역량 측정에 대한 비유
현재 AI 기술의 역량을 단일한 량으로 보려는 유혹이 있습니다. 즉, 주어진 과제 X가 현재 도구의 능력 범위 내에 있거나 그렇지 않다고 보는 것입니다. 그러나 실제로는 도구에 어떤 자원과 지원이 제공되는지, 그리고 그 결과를 어떻게 보고하는지에 따라 역량에 매우 큰 편차(수십 배의 차이)가 있습니다.
인간의 비유를 통해 이를 설명할 수 있습니다. 최근에 막을 내린 국제수학올림피아드(IMO)를 예로 들어보겠습니다. 이 대회의 형식은 각 나라가 6명의 고등학생 참가자로 구성된 팀을 꾸리고, 팀 리더(주로 전문 수학자)가 이들을 이끄는 방식입니다. 이틀에 걸쳐 각 참가자는 매일 4시간 30분 동안 어려운 수학 문제 3개를 풀어야 하며, 필기구와 종이만 사용할 수 있습니다. 이 시간 동안 참가자 간의 (또는 팀 리더와의) 의사소통은 허용되지 않지만, 문제의 표현에 대해 감독관에게 질문하여 명확히 할 수는 있습니다. 팀 리더는 채점 과정에서 IMO 심사위원단 앞에서 학생들을 위해 변호하지만, IMO 시험에 직접 관여하지는 않습니다.
IMO는 고등학생이 메달, 특히 금메달이나 만점을 받을 만큼 좋은 성적을 거두기 위한 매우 선택적인 수학적 성취의 척도로 널리 알려져 있습니다. 올해 금메달 커트라인은 42점 만점에 35점으로, 이는 6문제 중 5문제를 완벽하게 푸는 것에 해당합니다. 한 문제만 완벽하게 풀어도 "장려상"을 받습니다. 하지만 다음과 같이 형식을 변경하면 올림피아드의 난이도가 어떻게 변하는지 생각해보십시오.
- 학생들에게 세 문제에 대해 4시간 30분을 주는 대신, 각 문제를 푸는 데 며칠의 시간을 줍니다. (비유를 좀 더 확장하자면, 학생에게는 여전히 4시간 30분만 주어지지만, 팀 리더가 학생들을 일종의 비싸고 에너지 소모가 많은 시간 가속 장치에 넣어 그 시간 동안 학생들에게는 몇 달 또는 몇 년의 시간이 흐르는 공상 과학 시나리오를 생각해보십시오.)
- 시험이 시작되기 전에 팀 리더가 학생들이 더 쉽게 작업할 수 있는 형식으로 문제를 다시 작성합니다.
- 팀 리더는 학생들에게 계산기, 컴퓨터 대수 패키지, 형식적 증명 보조 장치, 교과서 또는 인터넷 검색 기능을 무제한으로 이용할 수 있게 합니다.
- 팀 리더는 6명의 학생 팀이 동일한 문제에 대해 동시에 작업하게 하여, 각자의 부분적인 진행 상황과 보고된 막다른 길에 대해 서로 소통하게 합니다.
- 팀 리더는 학생들에게 유리한 접근 방향으로 유도하는 힌트를 주고, 학생 중 한 명이 성공할 가능성이 희박한 방향으로 너무 많은 시간을 보내고 있으면 개입합니다.
- 팀의 6명 학생이 모두 풀이를 제출하지만, 팀 리더는 "최고의" 풀이만 선택하여 대회에 제출하고 나머지는 버립니다.
- 팀의 학생 중 누구도 만족스러운 풀이를 얻지 못하면, 팀 리더는 아무런 풀이도 제출하지 않고, 그들의 참여가 기록되지 않은 채 조용히 대회에서 기권합니다.
이러한 각 형식에서 제출된 풀이는 기술적으로는 팀 리더가 아닌 고등학생 참가자들이 생성한 것입니다. 그러나 이러한 형식 변경에 따라 보고되는 학생들의 대회 성공률은 극적으로 영향을 받을 수 있습니다. 표준 시험 조건 하에서는 동메달 성적에도 미치지 못할 수 있는 학생이나 팀이, 위에 제시된 일부 수정된 형식 하에서는 금메달 성적을 거둘 수도 있습니다.
따라서 경쟁 팀이 스스로 선택하지 않은 통제된 테스트 방법론이 없는 상황에서는, IMO와 같은 대회에서 다양한 AI 모델의 성능을 서로 비교하거나, 이러한 모델과 인간 참가자의 성능을 일대일로 비교하는 것에 대해 신중해야 합니다.
이와 관련하여, 대회에 앞서 방법론이 공개되지 않은 자체 보고된 AI 대회 성능 결과에 대해서는 논평하지 않겠습니다.
2. 테렌스 타오의 주장에 대한 나의 생각
테렌스 타오의 글은 AI가 작동되는 방식을 인간의 활동에 비유하며 그 본질을 꿰뚫어 봅니다. 몇 가지 핵심적인 비유를 살펴보겠습니다.
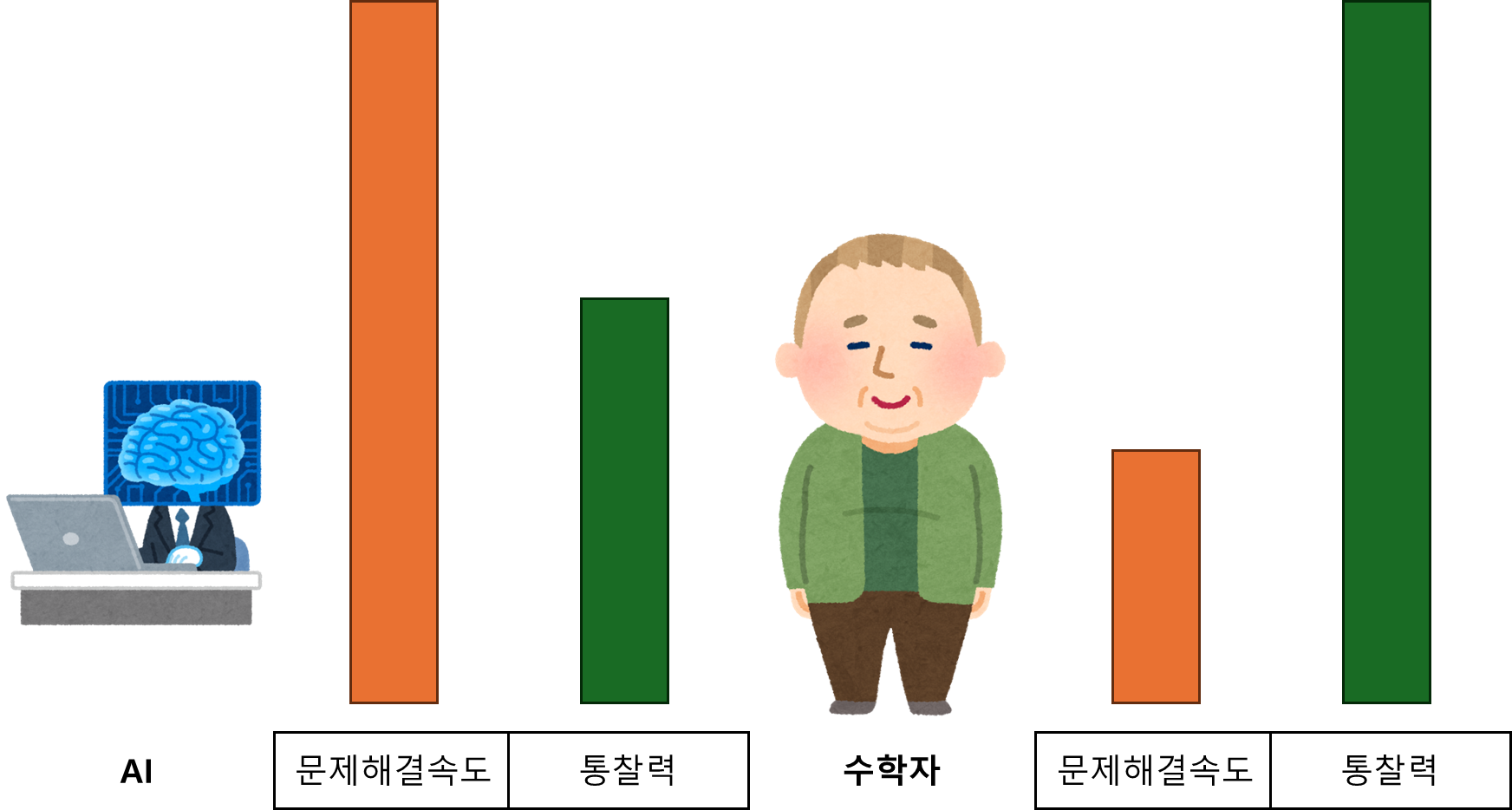
이는 AI가 막대한 에너지를 투입하여 인간보다 훨씬 빠른 속도로 사고하고 탐색할 수 있음을 의미합니다. 속도가 빠르면 통찰력이 부족하더라도 더 많은 경우의 수를 시도하여 좋은 결과를 낼 수 있는 것처럼 보일 수 있습니다.
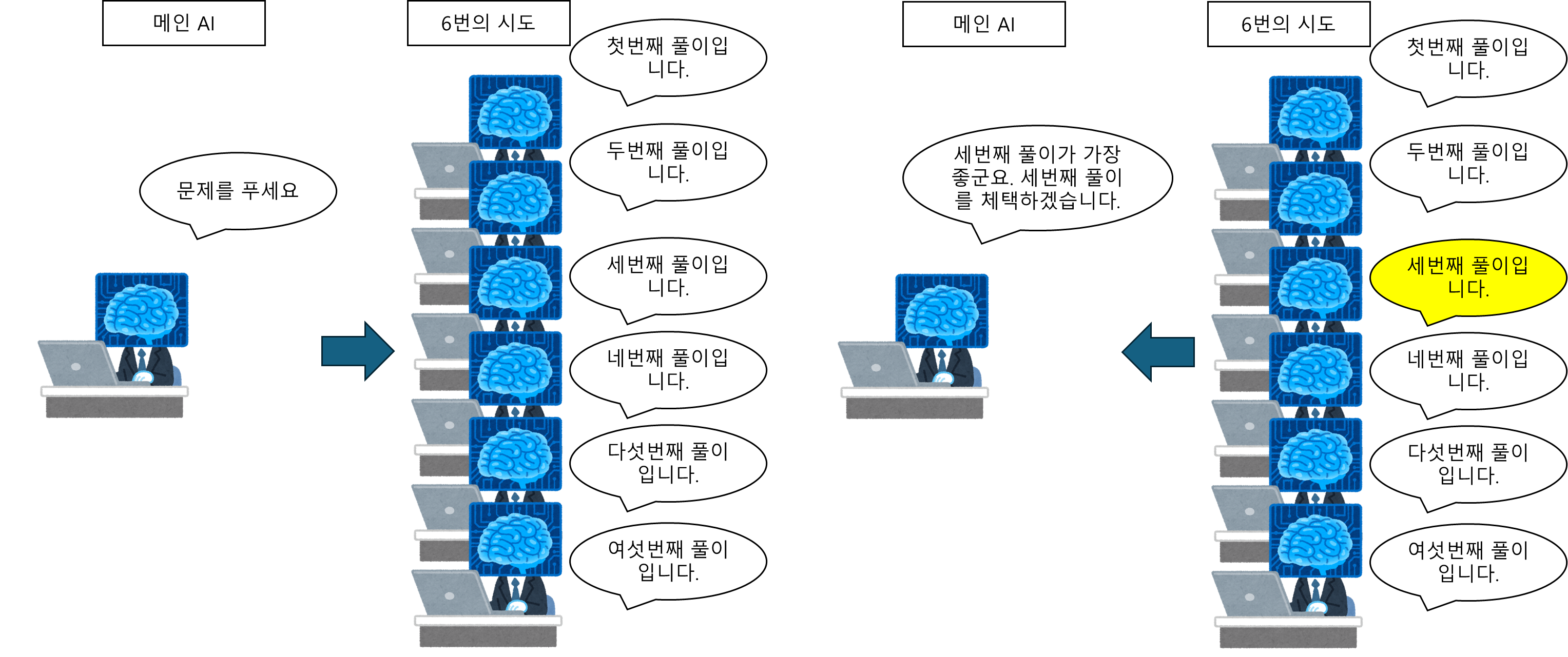
이것은 AI가 여러 개의 결과물을 생성하면, 인간 검토자가 그중 가장 뛰어난 것을 선택하는 과정을 비유합니다. 이는 단 하나의 풀이에 집중하는 개별 인간과의 직접적인 비교가 왜 어려운지를 보여줍니다.
이는 AI가 풀이 과정에서 잘못된 길로 빠졌을 때, 인간이 올바른 방향으로 이끌어주는 '프롬프트 엔지니어링'이나 '미세 조정' 과정을 의미합니다.
테렌스 타오의 주장 중에는 "ChatGPT가 IMO 문제를 풀 때 인터넷에 접근 가능했다"는 뉘앙스의 주장이 있는데, 이는 사실이 아닐 가능성이 높습니다. OpenAI와 같은 기업들은 모델의 성능을 냉정하게 평가받아야 하며, AI 분야는 성능을 숨기기 어렵기 때문에 굳이 성능을 과장할 이유가 적습니다.
그러나 그의 다른 주장들은 타당함에도 불구하고, 최종 결론에 대해서는 동의하기 어려운 부분이 있습니다.
인간과 AI의 지적 대결은 이번이 처음이 아닙니다. 딥블루와 알파고의 사례에서 보았듯이, AI는 테스트 과정에서 가용할 수 있는 모든 자원을 투입하여 성능의 한계를 보여주었습니다. 누구도 그들의 성능을 의심하지 않았습니다. AI가 무엇을 할 수 있는지 그 잠재력의 끝을 확인하는 과정에서 자원을 제한하는 것은 무의미합니다.
다른 과학 및 기술 분야에서도 마찬가지입니다. 입자가속기는 새로운 입자를 발견하기 위해 가능한 한 거대하게 지어지며, 핵실험은 그 위력의 한계를 알기 위해 모든 기술을 동원합니다. IMO는 단지 어려운 수학 문제를 푸는 시험일 뿐, 여기에 AI와 인간의 비교를 신중히 해야 한다는 주장은 AI의 본질을 파악하는 데 있어 오히려 방해가 될 수 있습니다.
AI의 성능을 평가할 때 투입된 에너지를 따지는 것은 AI 도입을 고려하는 기업의 몫입니다. AI 그 자체의 능력을 통찰하고자 할 때는, AI가 어떤 결과물을 내놓는지에 집중해야 합니다.
이전 글에서도 언급했듯이, 수학은 인간 지성을 평가하는 중요한 척도이며 IMO 금메달은 상징적인 의미가 큽니다.
물론, 테렌스 타오와 같은 위대한 수학자의 입장에서 AI가 단순히 문제를 풀었다는 결과만으로 그 수학적 역량을 온전히 인정하기 어렵다는 점은 충분히 이해할 수 있습니다. 하지만 이는 AI의 능력을 평가하는 여러 관점 중 하나일 뿐, 그 가능성을 제한적으로 해석해서는 안 될 것입니다.
'AI' 카테고리의 다른 글
| Google Deep Mind의 IMO 금메달 (2) | 2025.07.22 |
|---|---|
| 가장 자연스러운 영상 제작 AI - VEO3 (0) | 2025.07.20 |
| 한국형 AI는 어디까지 왔을까? - solar pro2 (3) | 2025.07.20 |
| gemini code assist후기 (아직 많이 멀었다) (0) | 2025.07.20 |
| chatgpt 유료구독을 해야하는 이유 (0) | 2025.07.19 |